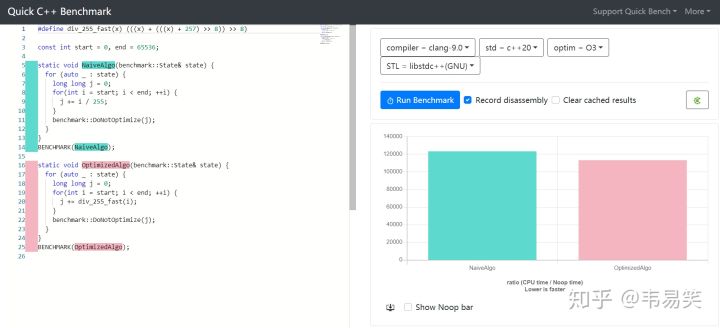
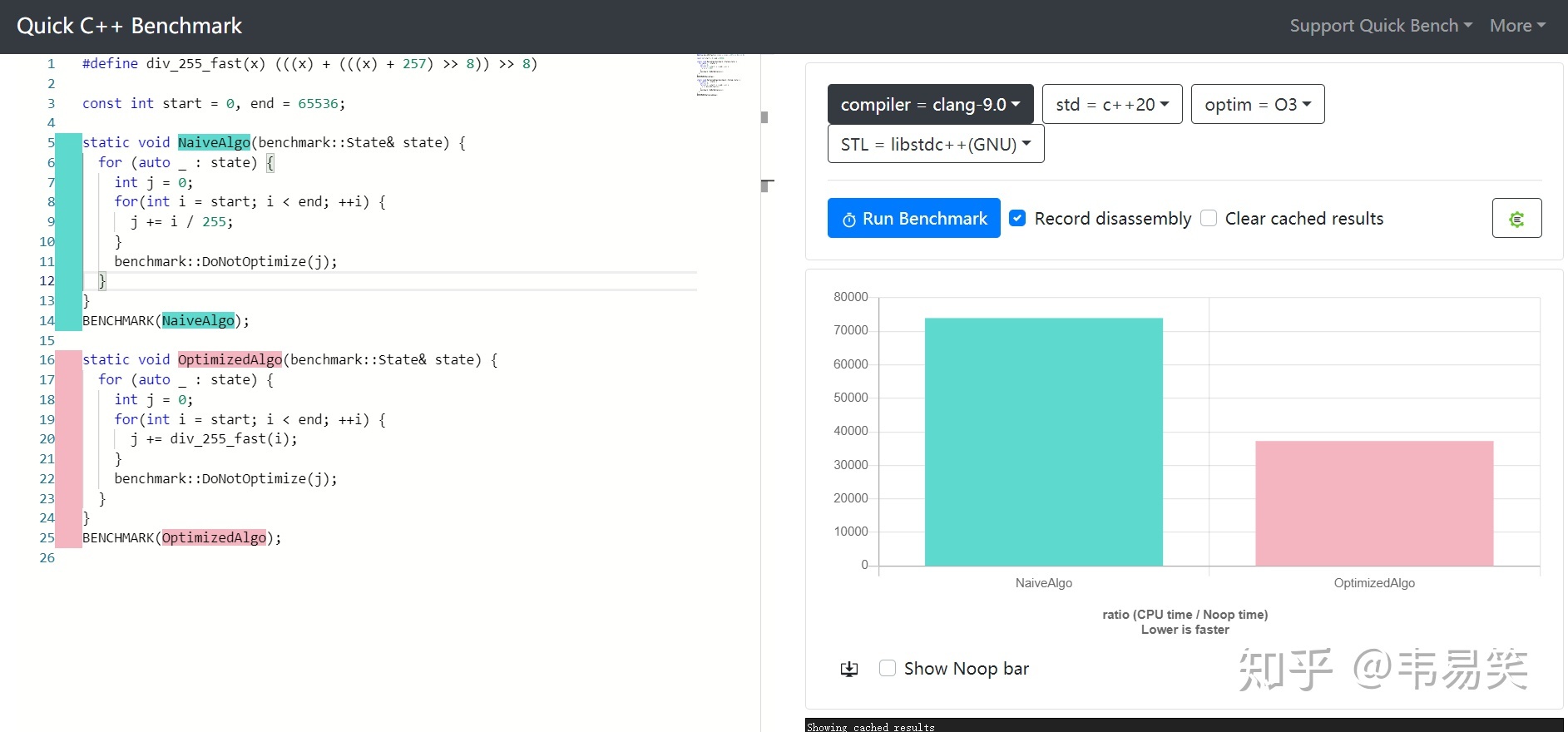
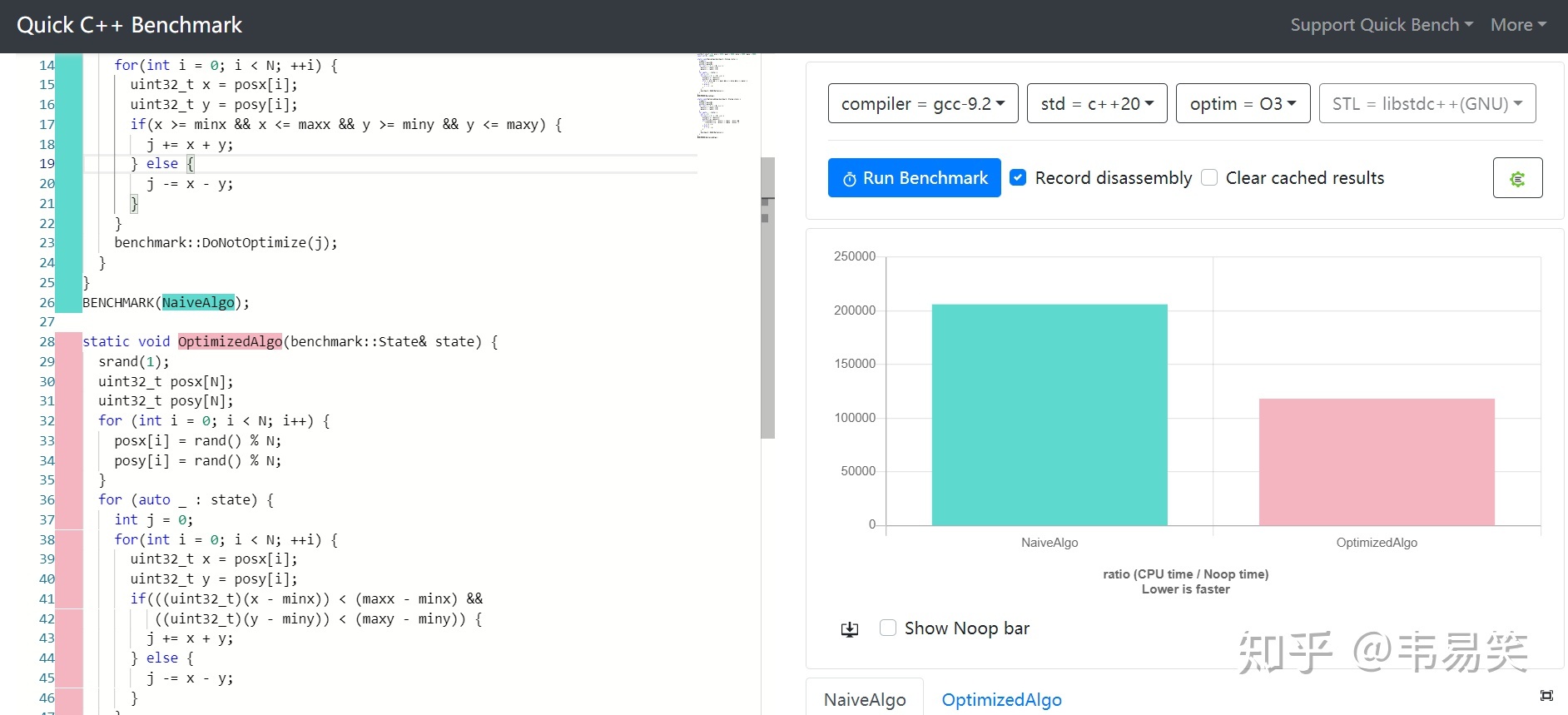
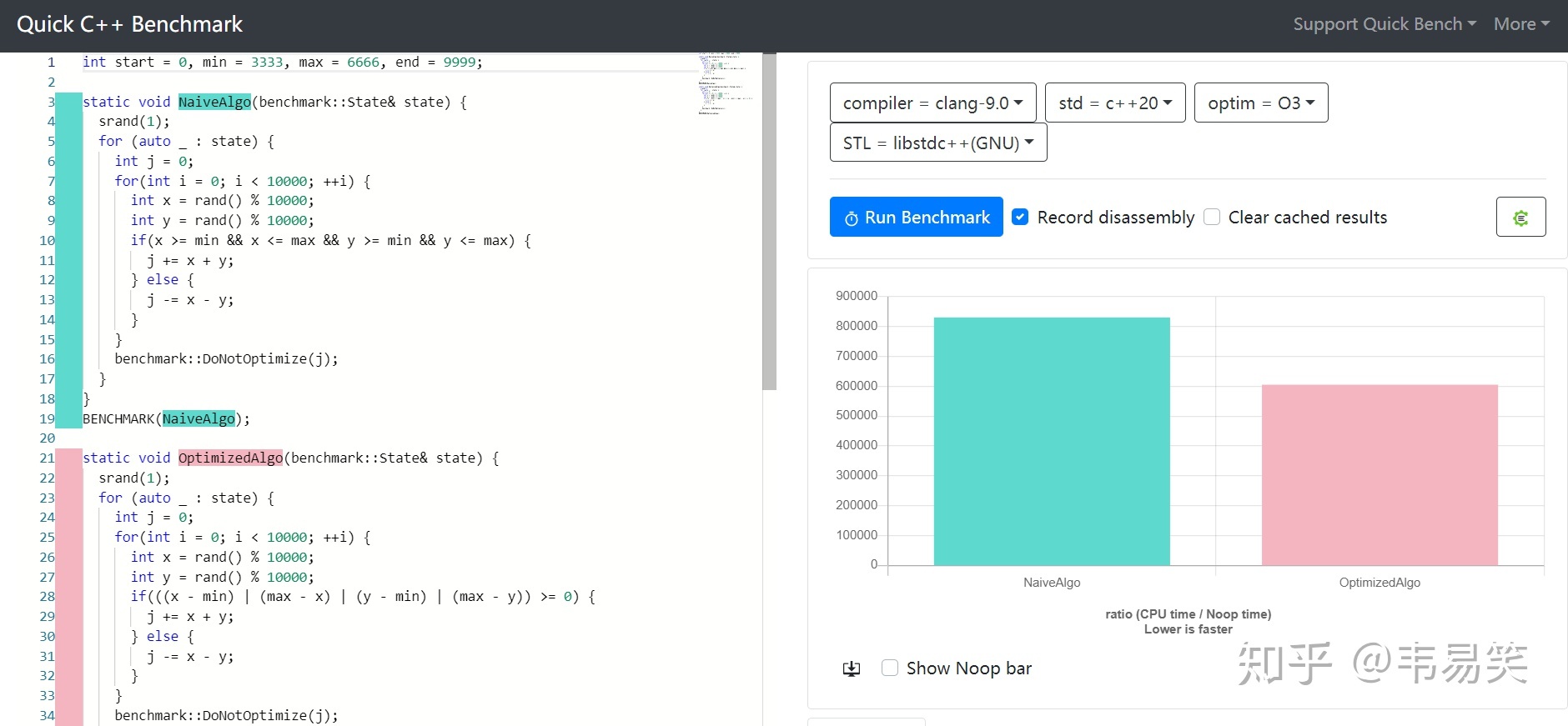
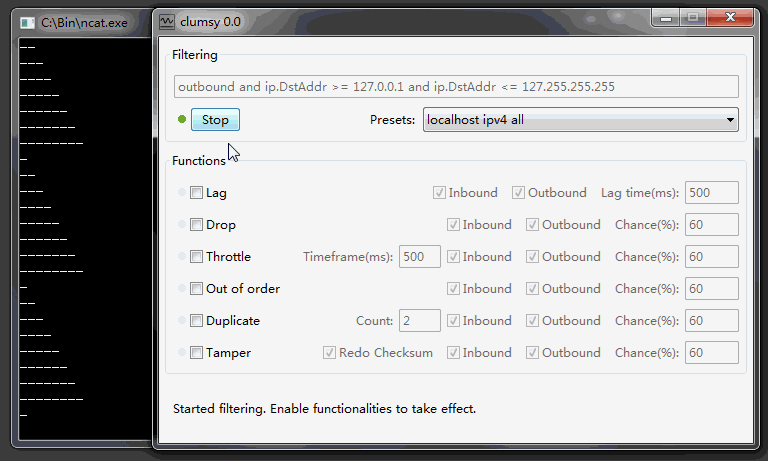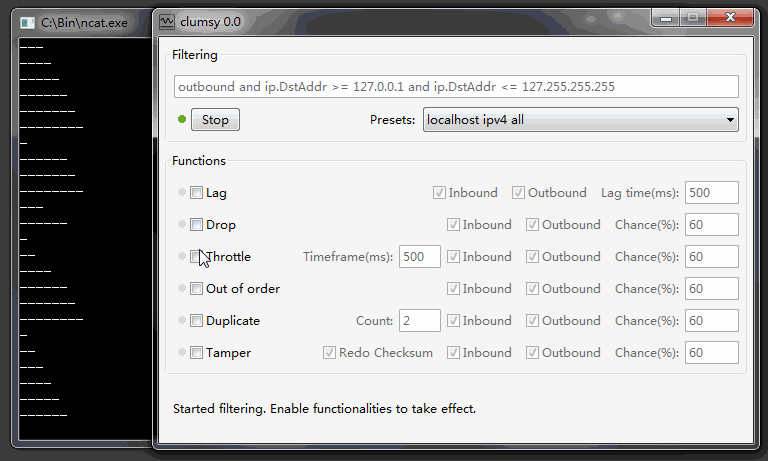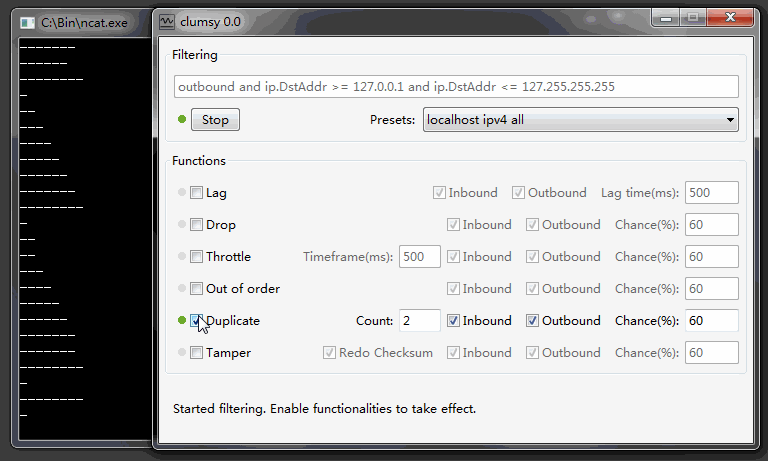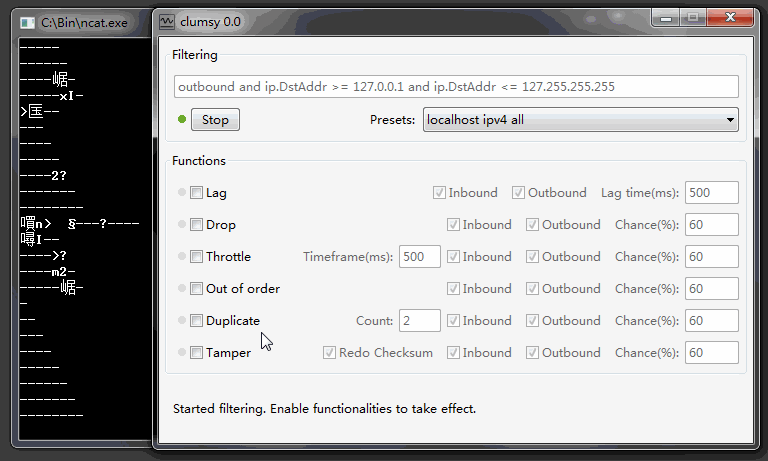
关于游戏同步的话题说的太多了,我是不想再谈了,但是碰到一些含糊和容易引起混淆的地方,必须澄清一下,云风在 2018 年在《lockstep 网络游戏同步方案》中有一段:
首先,我认为把 lockstep 翻译成帧同步,还有与之对应的所谓“状态同步” (我在多次面试中听过这个名词),都是对同步算法的错误理解造成的。把自己所理解的算法牵强附会到已有的在欧美游戏先行者中经过实践的方案上。
最近网易雷火工作室的一篇文章《细谈网络同步在游戏历史中的发展变化》谈到了类似的观点,那么为了避免产生混乱,有必要对 “帧同步”这个说法做一次澄清。
帧同步不是单指某个具体算法,而是范指 “保证每帧(逻辑帧)输入一致” 的一系列算法,传统实现有帧锁定,乐观帧锁定,lockstep,bucket 同步等等,但凡满足“每帧输入一致”的方法皆可以归纳为帧同步类别,至于要不要回滚?服务端要不要跑一套完整逻辑?操作要不要是键盘鼠标?还是高阶命令?客户端要不要像视频播放器一样保证平滑缓存 1-2 帧?或者要不要保证平滑加一层显示对象的坐标插值?这些都是具体优化手段。
我在 2009 年公司应届生培训的《服务端开发培训》课程内,最早开始做同步技术培训:
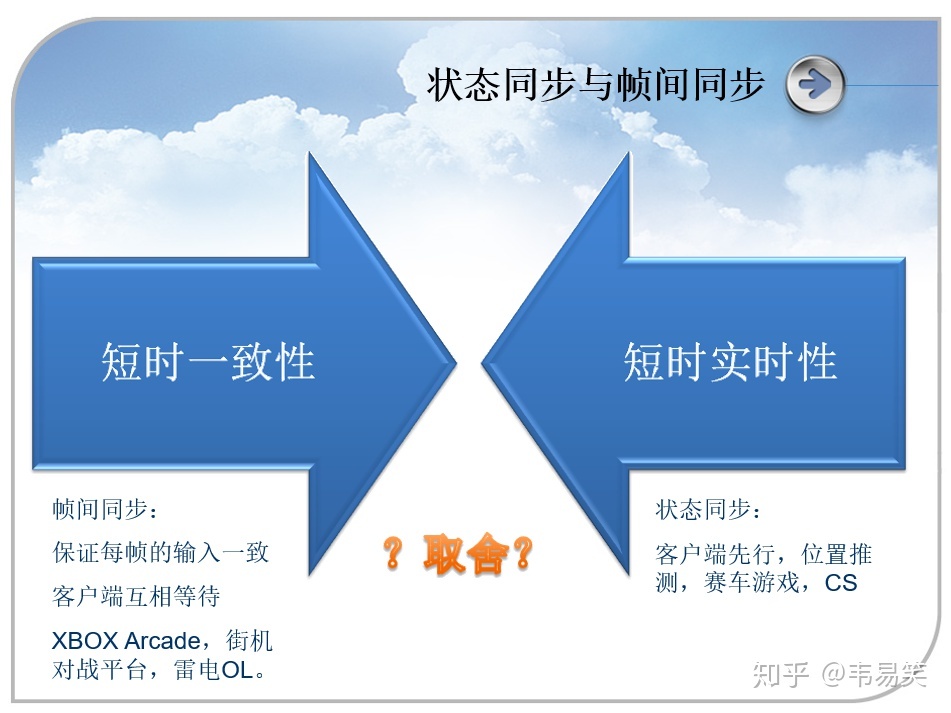
这个 “帧间同步”喊着喊着就被喊成了“帧同步”,这应届生培训持续了好几年,应该数百人听过这个课程,后面的讲师又接着迭代这个 ppt 接着讲了好几年,听过的应届生们自己摸索后,又写了新的技术分享放到网上,兴许从那时候 “帧同步”和 “状态同步”的说法就流传开了吧。
(点击 Read more 展开)
![]()