
《游戏服务端发展史》转载请著名出处:http://www.skywind.me/blog/archives/1301
类型4:第三代游戏服务器 2007
从魔兽世界开始无缝世界地图已经深入人心,比较以往游戏玩家走个几步还需要切换场景,每次切换就要等待 LOADING个几十秒是一件十分破坏游戏体验的事情。于是对于 2005年以后的大型 MMORPG来说,无缝地图已成为一个标准配置。比较以往按照地图来切割游戏而言,无缝世界并不存在一块地图上面的人有且只由一台服务器处理了:

![]()
《游戏服务端发展史》转载请著名出处:http://www.skywind.me/blog/archives/1301
类型4:第三代游戏服务器 2007
从魔兽世界开始无缝世界地图已经深入人心,比较以往游戏玩家走个几步还需要切换场景,每次切换就要等待 LOADING个几十秒是一件十分破坏游戏体验的事情。于是对于 2005年以后的大型 MMORPG来说,无缝地图已成为一个标准配置。比较以往按照地图来切割游戏而言,无缝世界并不存在一块地图上面的人有且只由一台服务器处理了:
![]()
手游页游和端游,本质上没有区别,区别的是游戏类型:
《游戏服务端架构发展史》转载请著名出处:http://www.skywind.me/blog/archives/1265
类型1:卡牌,跑酷等弱交互服务端
卡牌跑酷类因为交互弱,玩家和玩家之间不需要实时面对面PK,打一下对方的离线数据,计算下排行榜,买卖下道具即可,所以实现往往使用简单的 HTTP服务器:

登录时可以使用非对称加密(RSA, DH),服务器根据客户端uid,当前时间戳还有服务端私钥,计算哈希得到的加密 key 并发送给客户端。之后双方都用 HTTP通信,并用那个key进行RC4加密。客户端收到key和时间戳后保存在内存,用于之后通信,服务端不需要保存 key,因为每次都可以根据客户端传上来的 uid 和 时间戳 以及服务端自己的私钥计算得到。用模仿 TLS的行为,来保证多次 HTTP请求间的客户端身份,并通过时间戳保证同一人两次登录密钥不同。
![]()
这个题目本来不想讨论,现实生活中我是一个尊重他人的人,而尊重他人最重要的是尊重他人的选择,尊重他人的价值观和梦想。但是身边太多惨痛的教训,让我有种不吐不快的想法,大家偶尔也该停下忙碌的脚步来想想自己要走的路,也是一件很有意义的事情,所以如果言语中我伤害了你的梦想,请你绕道而行:
下有地雷,玻璃们请小心绕路:
![]()
关于行为树的实现,我在网上看到几个实现版本都对节点规划了running状态,表示节点的动作未执行完毕,每次执行时从上次未执行完毕的节点开始执行而跳过之前已经执行完毕的节点。
问题在于,处于同一selector节点下的子节点,位置越靠前的节点优先级是越高的,如果因为running恢复机制而跳过了已经执行完毕的节点,岂不是无法实现“打断”现有逻辑的需求?
我想问,节点running状态的引入是为了解决什么问题?为什么不每次都top-down执行所有节点?
http://www.zhihu.com/question/29486474
1. 行为树肯定要有 RUNNING状态的,否则你长时间做一件事情很难描述呀,比如你先做“走过去”,再做“采矿”再做“返回”,一颗行为树就表达完了。每件事情都是持续的,如果没有RUNNING,那其实就更像一颗“决策树”而非“行为树”了。
2. 假设你有三层状态机,行为树也只会用在最后一层,头两层都是一些“确定的动作”,不需要行为树来弄,比如“跑过去”,“采矿”这些分解动作,本来变化也不多,如果这都要行为树来弄的话,你的开发反而会很累。
3. 行为树是“树形逻辑”,“树形状态变迁”,但是有些时候逻辑不是树形的,比如就是个纯粹的是有向图的,这种情况下非要用行为树的话,要打比较多Patch
4. 针对你说的“停止”,问题,状态机/行为树,肯定要可以随时打断安排新任务的,具体的做法可能是,update的时候传入一个事件(比如时钟,或者结束),就像tcp的状态机,时钟和网络包都是它的输入,如果不能处理输入,那你做出来的东西只会自顾自的在屏幕上动来动去罢了。
5. 针对实现停止,有三种做法,一种是节点前判断,一种是行为树跑完后,都要跑一个通用的状态机;第二种是增加RESET整棵树的操作;第三种是通用状态机来处理任务改变的消息,一旦改变就复位树,或者调用一颗新的树,比如你把“巡逻”,“逃避”,“进攻”,写成了三颗不同的行为树,相当于一个“高级状态”来用。
PS:由于国内单机游戏凋零,网游类型单一,早年国内说 AI 都在说寻路,而这两年说 AI 大家都在说行为树。行为树是好用的,但是最近两年有些滥用了。它不是银弹,不是什么问题都可以扔给行为树让它来解决的。
![]()
知乎上有人问:“贴吧都是十五六岁就用引擎写游戏的天才,大家怎么看?”,感觉现在做游戏真实一件幸福的事情呀,不尽想起当年开发游戏的各种艰辛。
现在做游戏很简单,大把代码给你参考,大把框架给你使用,Windows帮你作完了大部分事情。我们那个年纪写游戏时,家里还没有Internet,什么资料都查不到,什么开源引擎都没有,95年左右你要写一个游戏,你起码面临:
![]()
常用 MSVC写内嵌汇编需要兼容 GCC是一件头疼的事情,不是说你不会写 GCC的 AT&T风格汇编,而是说同一份代码写两遍,还要调试两遍,是一件头疼的事情,特别是汇编写了上百行的时候。于是五年前写过一个小工具,可以方便的进行转换,能把 MSVC/MASM的汇编转成纯 AT&T风格汇编,或者 GCC Inline风格汇编,自动识别寄存器和变量,还有跳转地址,并且自动导出。今天把他放上来,或许有用到的人吧。
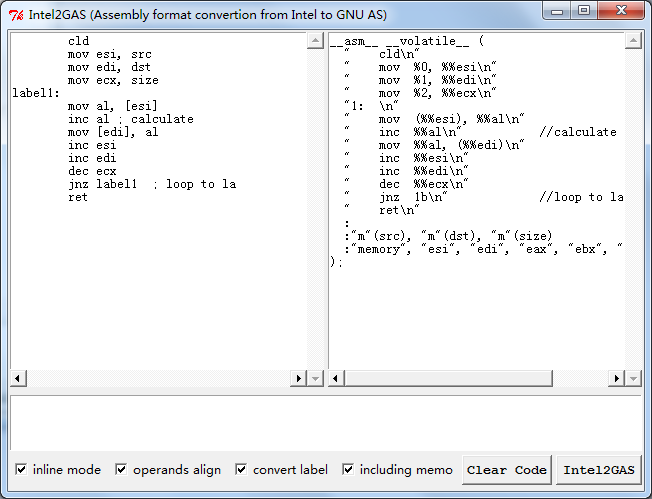
![]()
BehaviorTree:国内很多正式商用项目确实用了,不管RTS,还是RPG,而且用的还行,毕竟写AI一大半时间在调试上,有图形化的界面,调试起来更方便点,有的项目策划可以直接来写AI。值得花时间封装的东西,你做出一套来,以后其他项目都可以用,但是两个人一个多月的时间是最起码的,一个人写一个GUI编辑器,另一个人写 BehaviorTree的运行时,用你们熟悉的语言来写。包括若干基类,运行跟踪,状态单步,以及可以脱离游戏环境的调试方式。如果找到称手的AI框架,拿过来, 比如你可以评估下 U3D的 BehaviorTree的库和编辑器是否可以,能否集成到你的项目?我自己没有用过,我们用自己之前的一个实现。
NaviMesh:大部分情况最好不用,现在国内大部分游戏都是显示3D,但是内部数据还是2D的,比如地图,还是用的格子,在这种情况下,引入NaviMesh会逼迫你客户端使用全3D数据结构,并且逼迫你服务端从2D计算升级到3D计算,主要是 NaviMesh实现起来起码也要一个多月,然后要调试很久。确实很优秀,但是不要为了用它来增加整体项目复杂度,我同事之前实现过 NaviMesh,但是仅仅在试验项目里用了,正式线上产品开发时,我们还是选择用纯2D地图,上传统寻路。
![]()
程序员也有三六九等:
初等程序员靠知识来挣钱,会别人会的东西,喜欢折腾架构和框架,以掌握更多新潮东西而沾沾自喜,以模仿各种奇技淫巧重新实现一遍而四处炫耀,常见台词:“为啥还在用png存图片?为啥不用webp这种高压缩比的格式?”,“我们使用 Erlang的高并发特性来实现同时支持5万人的效果”,“我们使用RTMFP来降低流量成本,又使用H265来给用户提供更高品质的视频画质”,这些人能够迅速的学会各种项目需要的架构套件,以自己的生产力来挣钱。
高等程序员靠智慧挣钱,会别人不会的东西,上能抉择技术方向,下能解决性能瓶颈;讨论方案时,腾讯怎么做的,阿里怎么做的,我们该怎么做,如数家珍;写完代码后,初读让人赏心悦目,再读让人恍然大悟,三读让人心悦诚服。常见台词:“webp压缩比不高,我改了一版新webp,用H265帧内预测来保存RGB,用lzma2来保存alpha比webp好多了”,“erlang大家不熟悉,我做了一个库,让大家可以象写erlang一样来写C++,照顾大家开发习惯,又可以象erlang一样写多线程”。“Micheal Abrash这几行代码还有很大优化空间,其实性能还可以更好!”她们都是以解决别人不能解决的问题来挣钱。
上等程序员靠创新来挣钱,能促进行业的发展,在这个充满咨询的年代,学习大家都掌握的东西只是一个基本过程,没什么值得称道的,当你baidu上找不到方案,google里没有参考,国内外没有任何人能给你启示的时候,任然能够充满创造的分析问题,抽象问题,并解决问题。找到别人完全没有走过的路,创造前人从来没有创造过的东西,这是他们的价值所在。他们的常见台词是:“别烦我!”,“忙着呢!”,“谷歌搜呀,这都问我?”,上等程序员是国宝,他们的时间不应该浪费在无意义的事情上。
![]()