
传统神经网络最早我 2008 年我用 C 实现过一版,当时打算用它来炒股,结果一塌糊涂,不过程序是调试通顺了,主要实现了四个模块:
- 神经元:存储权重和激励函数,能够根据输入矢量计算出单一输出值。
- 层:由多个神经元组成一个层,不同层的输入输出可以串起来。
- 网络:由多个层串起来的网络结构。
- 训练:BP 算法训练每层上不同神经元的权重。
今年拿出来整理了一下,补写了很多注释,并又照着 C 版本实现了一个 Python 版本的(非 numpy 实现),没用 numpy,因为我觉得 numpy 矩阵套矩阵一串操作猛如虎,看起来会比较头疼,就用基础类型写清楚每步运算会更清晰一些。
项目地址:
包含两个实现,C 和 Python,神经网络的正向推理是很简单的,就是一路乘加调函数,直接看代码和注释问题不大;但要看懂后面的训练代码,会碰到 BP 算法这个难点,说白了就是要理解什么是链式求导:
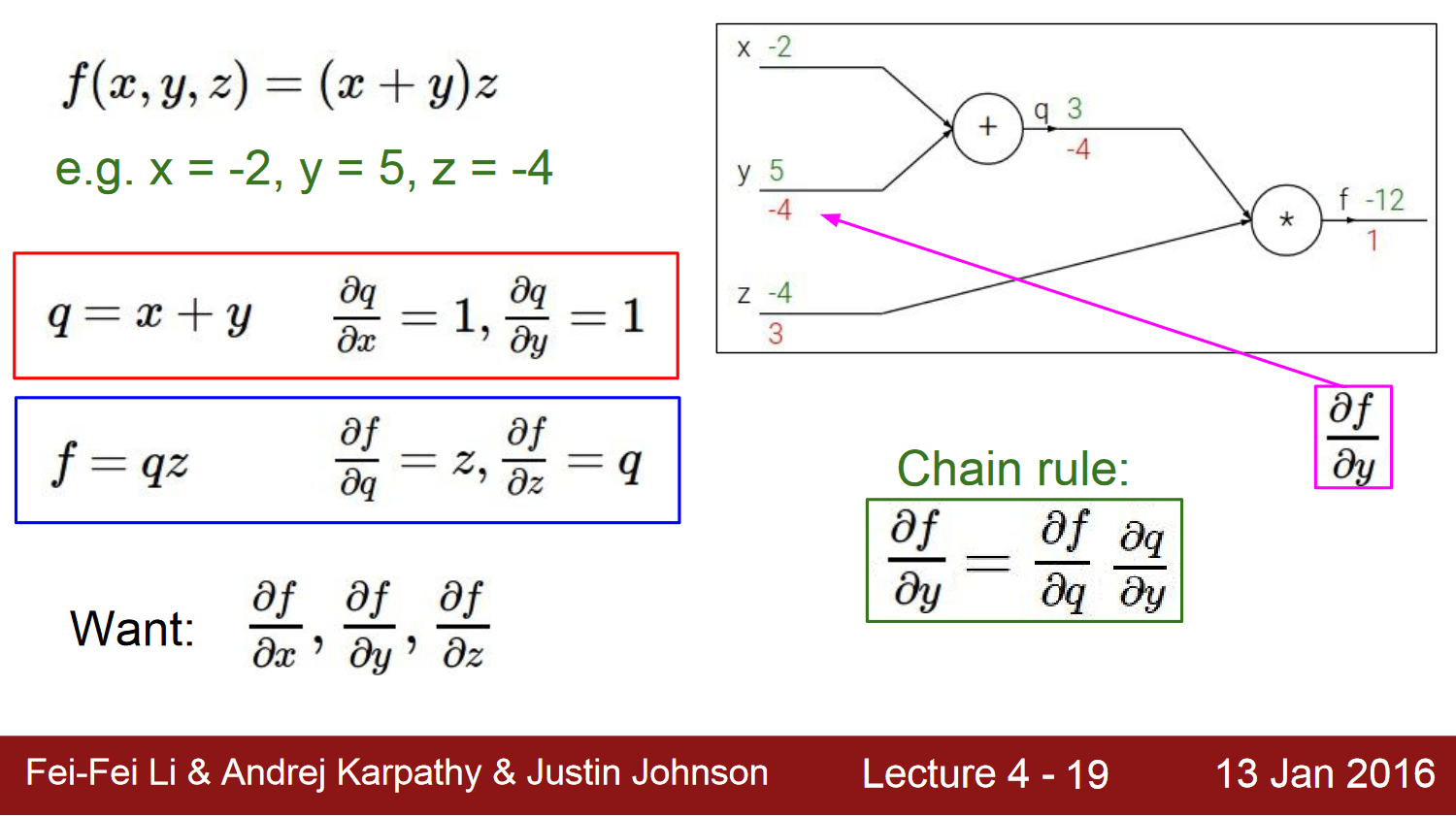
感觉讲的最清楚的就是 cs231n 的:
先前看过很多其它二手内容云里雾里讲半天,真的很难明白,但 cs231n 的视频,顺着一步步从最后推导过来,一下就能让你明白怎么回事情,建议找这节课的视频出来看一看。
看懂 Lecture 4,回过头来看代码也就可以对照一下,这些公式具体是怎么落到代码上的了。
Python 版本末尾有一段测试程序,训练和测试 XOR 计算,经过几轮训练,神经网络能够轻松的计算出 XOR 的结果来,但你可以试试,将前面随机数初始化权重那里注释掉,然后你就发现所有计算结果都是 0.5 了。
为什么呢?因为神经网络不像其它类似 kNN 或者 SVM 的模型,SVM 得到的是解析解,而神经网络目前的 BP 算法得到的只是近似数值解,很容易就陷入局部最优解里出不来,所以必须初始化随机数,初始化的不同,训练结果也有细微差异。
而 SVM 根本就不需要随机数初始化系数 C,全部用 0 初始化就行,最终得到的都是唯一最优的解析解,所以从理论模型上来讲,SVM 的确更漂亮,但不得不说,神经网络这个中医,很多时候还是挺管用的。
相关阅读:
![]()