
kNN (k-nearest neighbors)作为一个入门级模型,因为既简单又可靠,对非线性问题支持良好,虽然需要保存所有样本,但是仍然活跃在各个领域中,并提供比较稳健的识别结果。
说到这里也许你会讲,kNN 我知道啊,不就是在特征空间中找出最靠近测试样本的 k 个训练样本,然后判断大多数属于某一个类别,那么将它识别为该类别。
这就是书上/网络上大部分介绍 kNN 的说辞,如果仅仅如此,我也不用写这篇文章了。事实上,kNN 用的好,它真能用出一朵花来,越是基础的东西越值得我们好好玩玩,不是么?
第一种:分类
避免有人不知道,还是简单回顾下 kNN 用于分类的基本思想。
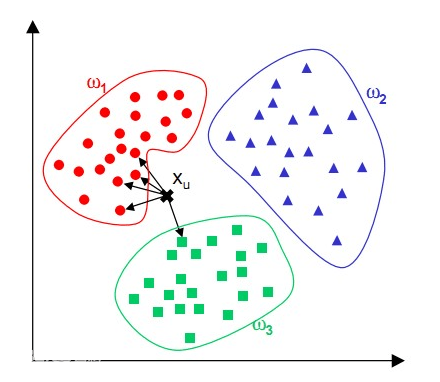
针对测试样本 Xu,想要知道它属于哪个分类,就先 for 循环所有训练样本找出离 Xu 最近的 K 个邻居(k=5),然后判断这 K个邻居中,大多数属于哪个类别,就将该类别作为测试样本的预测结果,如上图有4个邻居是圆形,1是方形,那么判断 Xu 的类别为 “圆形”。
第二种:回归
根据样本点,描绘出一条曲线,使得到样本点的误差最小,然后给定任意坐标,返回该曲线上的值,叫做回归。那么 kNN 怎么做回归呢?
你有一系列样本坐标(xi, yi),然后给定一个测试点坐标 x,求回归曲线上对应的 y 值。用 kNN 的话,最简单的做法就是取 k 个离 x 最近的样本坐标,然后对他们的 y 值求平均:
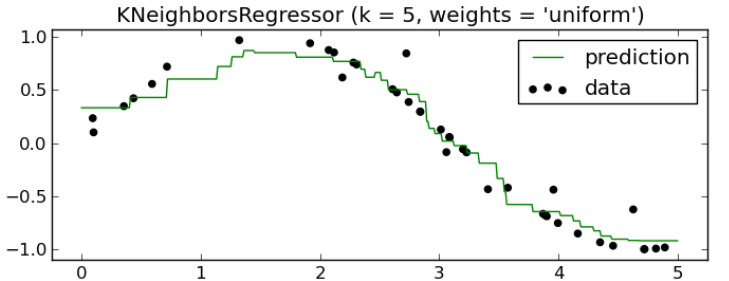
绿色是拟合出来的曲线,用的是 sklearn 里面的 KNeighborsRegressor,可以看得出对非线性回归问题处理的很好,但是还可以再优化一下,k 个邻居中,根据他们离测试点坐标 x 的距离 d 的倒数 1/d 进行加权处理:
w = [ 1 / d[i] for i in range(k) ]
y = sum([ (w[i] * y[i]) for i in range(k) ]) / sum(w)
如果 x 刚好和某样本重合,di = 0 的话,1/d 就正无穷了,那么接取该样本的 y 值,不考虑其他点(sklearn的做法),这样得到的 Y 值就相对比较靠谱了:
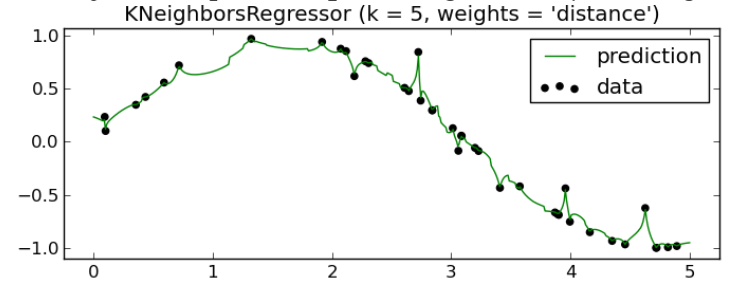
这样误差就小多了,前面不考虑距离y值平均的方法在 sklearn 中称为 uniform,后一种用距离做权重的称为 distance。
这曲线拟合的效果非常漂亮,你用梯度下降或者最小二乘法做拟合根本达不到这样的效果,即便支持向量回归 SVR 也做不到这么低的误差率。如果你觉得有些过拟合的话,可以调节 K 的值,比如增加 K 值,可以让曲线更加平滑一些。
更好的做法是 wi 设置为 exp(-d) ,这样 d=0 的时候取值 1,d 无穷大的时候,接近 0:
w[i] = math.exp(-d[i])
这样即 x 和某个训练样本重合或者非常接近也不会把该 wi 弄成无穷大,进而忽略其他样本的权重,避免了 sklearn 里面那种碰到离群点都非要过去绕一圈的问题,曲线就会更平滑。
第三种:One-class 识别
One-class 分类/识别又称为:异常点/离群点检测,这个非常有用。假设我们的 app 需要识别5种不同的用户手势,一般的分类器只会告诉你某个动作属于 1-5 哪个类型,但是如果是用户进行一些非手势的普通操作,我们需要识别出来“不属于任何类型”,然后需要在手势模块中不进行任何处理直接忽略掉。
这个事情用传统分类器非常困难,因为负样本是无穷多,多到没法列举所有额外的手势,我们只能收集正样本。这和 0-9 数字手写识别是一样的,比如用户写了个 A 字母,我们需要判断某个输入图像不是 0-9 中任何一个,但是我们除了 0-9 的样本外没法枚举所有例外的可能。
这时候 One-class 识别器一直扮演着举足轻重的作用,我们将 0-9 的所有样本作为“正样本”输入,测试的时候检测检测测试值是否也属于同类别,或者属于非法的负类别。kNN 来做这件事情是非常容易的,我们用 NN-d 的本地密度估计方法:
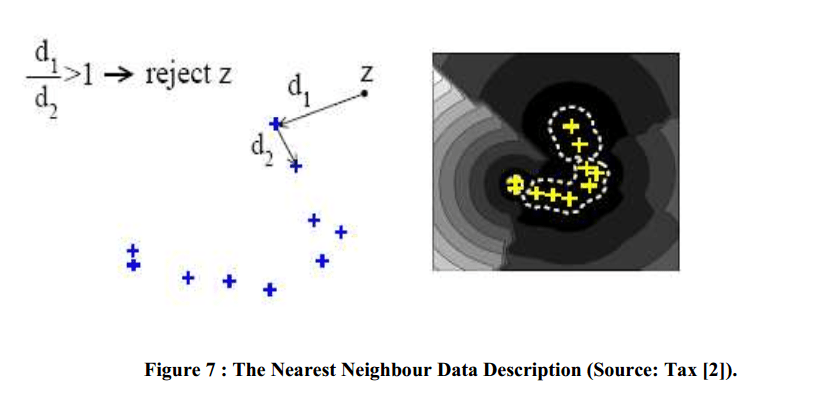
方法是对待测试样本 z ,现在训练样本中找到一个离他最近的邻居 B,计算 z 到 b 点的距离为 d1,然后再在训练样本中找到一个离 B 最近的点 C,计算 BC 距离为 d2,如果:
d1 <= alpha * d2 # alpha 一般取 1
那么接受 z 样本(识别为正类别),否则拒绝它(识别为负类别)。这个方法比较简单,但是如果局部样本太密集的话,d2 非常小,容易识别为负类别被拒绝。所以更成熟的做法是在训练样本中找到 k 个离 B 最近的样本点 C1 – Ck,然后把 d2 设置成 C1 – Ck 到 B 的距离的平均值。这个方法称为 kNN-d,识别效果比之前只选一个 C 的 NN-d 会好很多。
进一步扩展,你还可以选择 j 个离 z 最近的 B 点,用上面的方法求出 j 个结果,最后投票决定 z 是否被接受,这叫 j-kNN-d 方法,上面说到的方法就是 j = 1 的特殊情况。
对比 SVM 的 ONE_CLASS 检测方法,(j) kNN-d 有接近的识别效果,然而当特征维度增加时,SVM 的 ONE_CLASS 检测精度就会急剧下降,而 (j) kNN-d 模型就能获得更好的结果。
LIBSVM 里的三大用法:分类,回归,ONE_CLASS(离群点检测),同时也是监督学习中的三类主要问题,这里我们全部用 kNN 实现了一遍,如果你样本不是非常多,又不想引入各种包依赖,那么 kNN 是一个最简单可靠的备用方案。
第四种:搭配核函数
俗称 Kernel based kNN,SVM 之所以取得较大发展就是在引入核函数之后,而核函数并不是 SVM 特有,其他模型也都可以嫁接核函数,这种方法统称为 “核方法”。
kNN 中最关键的一步就是求距离 d(xi, xj),这个距离有很多种求法,比如传统欧氏距离:
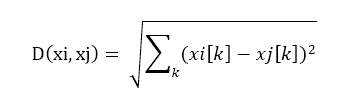
或者曼哈顿距离:
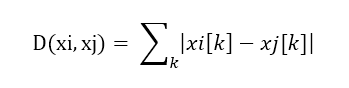
其实就是在距离函数上做文章,那么 kNN 引入核方法以后同样是在距离函数上做文章。
基本思想是将线性不可分的低维度特征矢量映射到线性可分的高维特征空间中(有可能是无限维),矢量 x 映射到高维空间后称为 φ(x),那么核函数 K(xi, xj) 代表两个高维空间矢量的内积,或者点乘:
K(xi, xj) = φ(xi) . φ(xj)
常用的核函数和 SVM 一样,有这么几个,比如常用的高斯核(RBF):
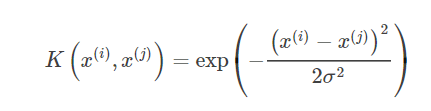
多项式核(POLY):
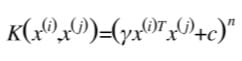
以及线性核(相当于传统欧式坐标系下点乘):
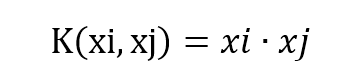
那么高维空间里两个点的距离,核化以后距离的平方可以表达为:
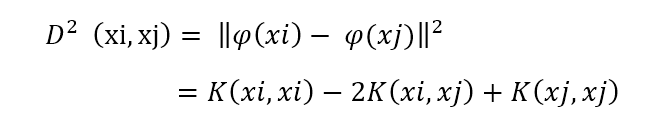
具体距离,就上上面公式的平方根。经过一次变换后,我们把 φ(xi) 和 φ(xj) 消除掉了,完全用关于 xi, xj 的核函数来表达距离,并不需要直接将 xi,xj 变换到高维空间才求距离,而是直接用核函数计算出来。
核方法如果你不熟悉,完全可以直接跳过,随机挑选一个核函数,带入到距离公式中用来求解 kNN 两个样本点的距离即可。
Kai Yu 在 《Kernel Nearest-Neighbor Algorithm》中论证过基于核方法的 kNN 分类器比传统 kNN 分类器表现的更好,因为仅仅是距离测量方式改变了一下,所以总体时间和传统 kNN 分类器仍然类似,但是效果好了很多:
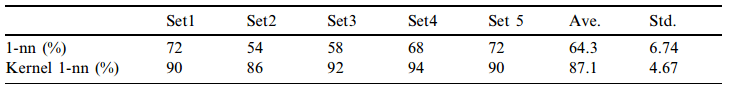
在不同的数据集上,核化 kNN 都能比传统 kNN 表现的更精确和稳定,他们使用 US Postal Service 数据和 BUPA Live Disorder 数据进行了验证,结果表明核化过的 kNN 分类器精度明显好于传统的 kNN,和 SVM 有得一拼:

同样,Shehroz Khan 等人在《Kernels for One-Class Nearest Neighbour Classification》验证了核化 kNN 在 One-Class 分类问题上取得了比 SVM One-class 更优秀的识别能力,在数个数据集上达到了 87% – 95% 的准确率。
第五种:搭配空间分割技术
针对大规模样本时 kNN 性能不高的问题,大家引入了很多空间分割技术,比如 kdtree:
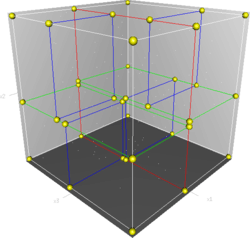
就是一种空间二分数据结构,构建很简单,选择一个切割坐标轴(所有样本再该坐标轴上方差最大)并将样本按该坐标轴的值排序,从中位切割成左右两个部分,然后继续递归切割,直到当前节点只有一个样本为止。
搜索的话就先递归找到目标点 z 所在的叶子节点,以该节点包含的样本 x 作为 “当前最近点”,再以 x 到 z 的距离 d 为半径,z 为圆心对整棵树进行递归范围搜索(如果某子树范围和球体不相交就不往下递归),最近点一定落在该范围中,一旦找到更近的点就即时缩小范围。
kdtree 网上有很多文章和代码,篇幅问题不打算细说,只想强调一点,网上大部分 kdtree 都是帮你找到最近的邻居,但是最近的前 k 个邻居怎么找?大部分文章都没说,少部分说了,还是错的(只是个近似结果)。
你需要维护一个长度为 K 的优先队列(或者最大堆),再找到最近邻居的基础上,将兄弟节点邻近的样本都填充到队列里,直到队列里装满 k 个样本,此时以 z 为圆心,队列里第 k 个离 z 最近的样本为半径,对 kd 树做一次范围搜索(最近的 k 个点一定落在该半径内),搜索过程中不断更新优先队列并及时根据最新的第 k 个样本离 z 的距离调整半径。
这样你就能精确的找出前 k 个离 z 最近的样本了。kd 树和维度相关,当样本维度不高时,kd树很快,但是样本维度高了以后,kd树的性能就会开始下降了。同时 kd 树应为要计算坐标轴,所以仅仅适合欧氏空间里进行切割。
如果我们的 kNN 使用了核方法的话,kd 树就没法用了,因为那时候特征被映射到了高维的希尔伯特空间里去了,有可能无限维度,kd 树就得靠边站了。
所以我们需要超球体空间分割法。
第六种:超球体空间分割
其实就是 sklearn 里面的 ball-tree,也是一种空间二分法,但是它不依赖坐标轴,只需要求解两个样本之间的距离就能构造出来,这天生适合引入核技巧:
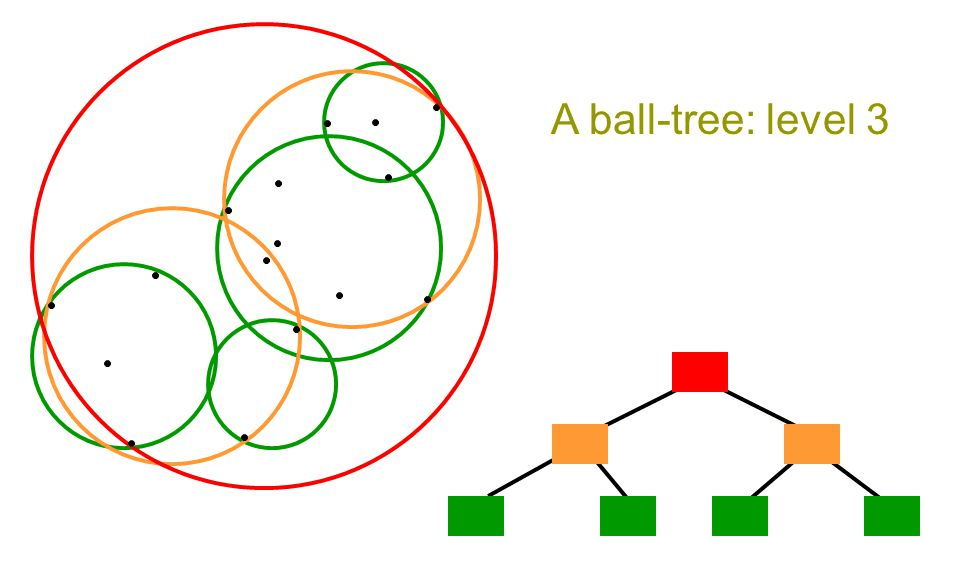
先从把所有样本放到一个超球体里开始,找到一个样本当球心 x0,使得所有其他样本到它的最大距离最短。然后找到一个离 x0 最远的点 x1,再找到离 x1 最远的点为 x2,然后把球体内所有样本分按照离 x1 最近分配给 x1,离 x2 最近就分配到 x2,然后构建两个子球体,再用上面的方法重新调整球心,然后递归下去,直到只包含一个样本,就不再切割,类似 kdtree。
还有一种做法是,将样本全部放在最底层的叶子节点上,每个叶子节点包含很多个样本,判断切割的方式是某个节点所包含的样本数如果少于阈值就不切割,否则进行切割。
进行范围搜索时和 kdtree 一样,先判断顶层节点的超球体是否和目标点 z 为圆心的目标球体相交(两个球体半径相加是否 >= 两球心之间的距离),如果不相交就跳过,相交的话继续把该节点的左右连个子球体拿过来判断相交,相交的话递归重复上面步骤,直到抵达叶子节点。
因为范围搜索也只需要依赖距离计算,和矢量到底有几个维度没有关系,也不需要像 kdtree 一样数坐标轴。因此 ball-tree 除了构造时间长点外,整体效率超过 kdtree,并且在矢量维度较高时,性能不会像 kdtree 一样下降,同时还支持核化版本的 kNN。
Kai Yu 等人用邮政数据进行过测试,当样本数量增加,不规律性上升时,即便映射到高维核空间里,也会出现线性不可分的情况,此时 SVM 的准确度就会下降,而装配了 ball-tree 的核化 kNN 此时就能表现出较高的准确性,同时兼具良好的查询性能。
第七种:冗余样本剔除
kNN 性能提升还可以通过在尽量不影响分类结果的情况下剔除冗余样本来提升性能,比如经典的 Condensed Nearest Neighbours Data Reduction 算法:

简单的讲就是先将样本点删除,然后用其他样本判断这个点,如果判断结果正确,则认为是一个冗余点,可以删除,如果不正确就要保留。
经过 reduction 过后的样本数据和原来的不一样,求解结果是一个近似解,只要误差可控,可以极大的提高 kNN 的搜索性能,效果如下:
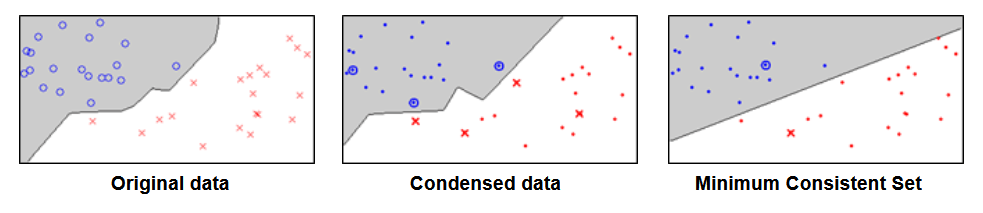
由圈圈变成点的是被剔除的样本,从左到右可以看出基本上是边缘部分的有限几个样本被保留下来了,结果非常诱人。
由于前面的空间分割技术并不会影响求解结果,所以大规模 kNN 一般是先上一个 ball-tree,还嫌不够快就上冗余样本剔除。唯一需要注意的地方是冗余剔除会影响 one-class 识别或其他依赖密度计算的东西,需要做一些额外处理。
话题总结
还有很多扩展用法,比如搜索前 k 个最近邻居时加一个距离范围 d,只搜索距离目标 d 以内的样本,这样可以间接解决部分 one-class 问题,如果同时离所有样本都很远,就能返回 “什么都不是”,这个 d 的选取可以根据同类样本的平均密度乘以一个 alpha 来计算。
在分类时,同时选取了多个邻居进行结果投票前同样可以根据距离对投票结果加权,比如前面提到的距离的倒数,或者 exp(-d) 当权重。
kNN 因为实现简单,误差可控(有证明),能处理非线性问题所以任然活跃在各种应用当中,前面咱们又介绍了如何拓展它的用途,如何引入核函数降低它误差,以及如何使用空间分割等技术提高它的性能。
总之,虽然很简单,但确实值得好好玩玩,一套实现良好的 kNN 库除了分类,回归,异常识别外,搭配超球体空间切割还能做很多聚类相关的事情。用的好了,它不会让你失望,可以成为你的一把有力的辅助武器,当主武器没法用时拿出来使唤下。
—
推荐阅读:
![]()
给大佬递茶